| Zurück | Weiter |
Funktionieren die bisher beschriebenen Tests auch mit Inhalten, die nicht ISO-8859-1 sind, beispielsweise mit russischen, griechischen oder chinesischen Texten und Metadaten?
Eine schwierige Frage. Denn auch wenn bei der Entwicklung von PDFUnit viel Wert darauf gelegt wurde, generell mit Unicode zu funktionieren, kann eine pauschale Antwort nur gegeben werden, wenn die eigenen Tests für PDFUnit selber mit „allen“ Möglichkeiten durchgetestet wurde. PDFUnit hat zwar etliche Tests für griechische, russische und chinesische Dokumente, aber für hebräische, arabische und japanische PDF-Dokumente nur wenig Tests. Insofern kann die eingangs gestellte Frage nicht abschließend beantwortet werden.
Die folgenden Tipps im Umgang mit UTF-8 Dateien lösen nicht nur Probleme im Zusammenhang mit PDFUnit. Sie sind sicher auch in anderen Situationen hilfreich.
Metadaten und Schlüsselwörter können Unicode-Zeichen enthalten.
Wenn Ihre Entwicklungsumgebung die fremden Fonts nicht unterstützt, können
Sie ein Unicode-Zeichen in Java mit \uXXXX schreiben, wie
hier das Copyright-Zeichen „©“ als \u00A9:
@Test public void hasProducer_CopyrightAsUnicode() throws Exception { String filename = "documentUnderTest.pdf"; AssertThat.document(filename) .hasProducer() .equalsTo("txt2pdf v7.3 \u00A9 SANFACE Software 2004") // 'copyright' ; }
Es wäre nun zu mühsam, für längere Texte den Hex-Code aller Buchstaben
herauszufinden. Deshalb stellt PDFUnit das kleine Programm
ConvertUnicodeToHex zur Verfügung.
Übergeben Sie den ausländischen Text als String an das Werkzeug,
entnehmen Sie der daraus erzeugten Datei anschließend den Hex-Code und fügen
ihn in Ihr Testprogramm ein. Eine genaue Beschreibung steht in Kapitel
9.12: „Unicode-Texte in Hex-Code umwandeln“.
Das Test mit Unicode sieht dann so aus:
@Test public void hasSubject_Greek() throws Exception { String filename = "documentUnderTest.pdf"; String expectedSubject = "Εργαστήριο Μηχανικής ΙΙ ΤΕΙ ΠΕΙΡΑΙΑ / Μηχανολόγοι"; //String expectedSubject = "\u0395\u03C1\u03B3\u03B1\u03C3\u03C4\u03AE" // + "\u03C1\u03B9\u03BF \u039C\u03B7\u03C7\u03B1" // + "\u03BD\u03B9\u03BA\u03AE\u03C2 \u0399\u0399 " // + "\u03A4\u0395\u0399 \u03A0\u0395\u0399\u03A1" // + "\u0391\u0399\u0391 / \u039C\u03B7\u03C7\u03B1" // + "\u03BD\u03BF\u03BB\u03CC\u03B3\u03BF\u03B9"; AssertThat.document(filename) .hasSubject() .equalsTo(expectedSubject) ; }
In Kapitel
13.11: „XPath-Einsatz“
wird beschrieben, wie PDFUnit-Tests zusammen mit XPath funktionieren.
Auch die XPath-Ausdrücke können Unicode enthalten. Im folgende Beispiel wird analysiert,
ob irgendein XML-Knoten unterhalb von rsm:HeaderExchangedDocument
das Zeichen mit dem Unicode \u20AC enthält:
@Test public void hasZugferdData_ContainingEuroSign() throws Exception { String filename = "ZUGFeRD_1p0_COMFORT_Kraftfahrversicherung_Bruttopreise.pdf"; String euroSign = "\u20AC"; String noTextInHeader = "count(//rsm:HeaderExchangedDocument//text()[contains(., '%s')]) = 0"; String noEuroSignInHeader = String.format(noTextInHeader, euroSign); XPathExpression exprNumberOfTradeItems = new XPathExpression(noEuroSignInHeader); AssertThat.document(filename) .hasZugferdData() .matchingXPath(exprNumberOfTradeItems) ; }
Vorsicht bei Daten, die aus dem Dateisystem gelesen werden. Deren
Interpretation ist vom Encoding des jeweiligen Dateisystems abhängig.
Deshalb ist jedes Java-Programm, das Dateien verarbeitet, also auch PDFUnit,
von der Umgebungsvariablen file.encoding abhängig.
Es gibt mehrere Möglichkeiten, diese Umgebungsvariable für den jeweiligen Java-Prozess zu setzen:
set _JAVA_OPTIONS=-Dfile.encoding=UTF8 set _JAVA_OPTIONS=-Dfile.encoding=UTF-8 java -Dfile.encoding=UTF8 java -Dfile.encoding=UTF-8
Während der Entwicklung von PDFUnit gab es zwei Tests, die unter Eclipse fehlerfrei liefen, unter ANT
aber mit einem Encoding-Fehler abbrachen. Die Ursache lag in der Java-System-Property
file.encoding, die in der DOS-Box nicht auf UTF-8 stand.
Der folgende Befehl löste das Encoding-Problem unter ANT nicht:
// does not work for ANT: ant -Dfile.encoding=UTF-8
Statt dessen wurde die Property so gesetzt, wie im vorhergehenden Abschnitt für Shell-Skripte beschrieben:
// Used when developing PDFUnit: set JAVA_TOOL_OPTIONS=-Dfile.encoding=UTF-8
In der pom.xml können Sie UTF-8 an vielen Stellen konfigurieren.
Die folgenden Code-Ausschnitte zeigen mehrere Beispiele, wählen Sie die passenden
für Ihr Problem:
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> </properties>
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.5.1</version> <configuration> <encoding>UTF-8</encoding> </configuration> </plugin>
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-resources-plugin</artifactId> <version>2.6</version> <configuration> <encoding>UTF-8</encoding> </configuration> </plugin>
Wenn Sie XML-Dateien in Eclipse erstellen, ist es nicht unbedingt nötig, Eclipse auf UTF-8 einzurichten, denn XML-Dateien sind auf UTF-8 voreingestellt. Für andere Dateitypen ist aber die Codepage des Betriebssystems voreingestellt. Sie sollten daher, wenn Sie mit Unicode-Daten arbeiten, das Default-Encoding für den gesamten Workspace auf UTF-8 einstellen:
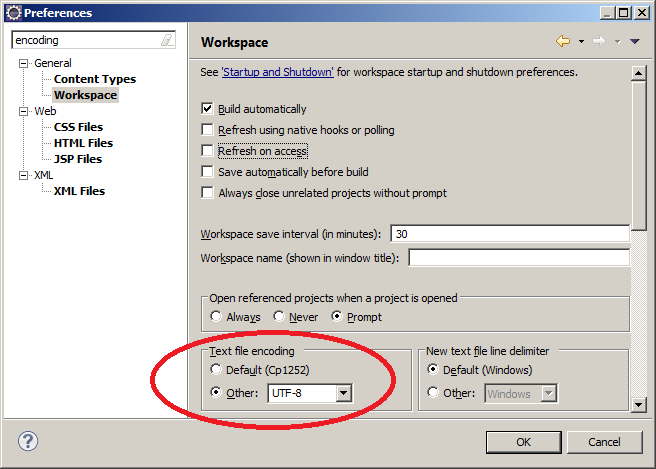
Abweichend von dieser Standardeinstellung können einzelne Dateien in einem anderen Encoding gepeichert werden.
Wenn Tests fehlschlagen, die auf Unicode-Inhalte testen, kann es sein, dass Eclipse oder ein Browser die Fehlermeldung nicht ordentlich dargestellen. Ausschlaggebend dafür ist das File-Encoding der Ausgabe, das von PDFUnit selber nicht beeinflusst werden kann. Wenn Sie in Eclipse, ANT oder Maven dafür gesorgt haben, dass „UTF-8“ als Codepage verwendet wird, sind die meisten Probleme beseitigt. Danach können noch Zeichen aus der Codepage „UTF-16“ die Darstellung der Fehlermeldung korrumpieren.
Das PDF-Dokument im nächsten Beispiel enthält einen Layer-Namen, der UTF-16BE-Zeichen enthält. Um die Wirkung der Unicode-Zeichen in der Fehlermeldung zu zeigen, wurde der erwartet Layername bewusst falsch gewählt:
/** * The name of the layers consists of UTF-16BE and contains the * byte order mark (BOM). The error message is not complete. * It was corrupted by the internal Null-bytes. */ @Test public void hasLayer_NameContainingUnicode_UTF16_ErrorIntended() throws Exception { String filename = "documentUnderTest.pdf"; // String layername = "Ebene 1(4)"; // This is shown by Adobe Reader®, // "Ebene _XXX"; // and this is the used string String wrongNameWithUTF16BE = "\u00fe\u00ff\u0000E\u0000b\u0000e\u0000n\u0000e\u0000 \u0000_XXX"; AssertThat.document(filename) .hasLayer() .equalsTo(wrongNameWithUTF16BE); ; }
Wenn die Tests mit ANT ausgeführt wurden, zeigt ein Browser die
von PDFUnit erzeugte Fehlermeldung fehlerfrei an, einschließlich
der Zeichenkette þÿEbene _XXX am Ende:

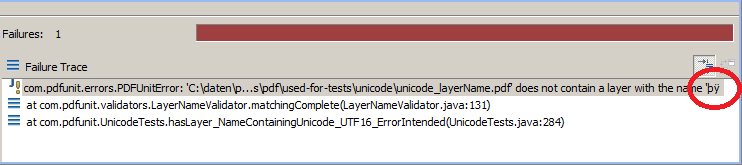
Eclipse dagegen hat in der JUnit-View Probleme mit den Null-Bytes.
Die Meldung
'...\unicode_layerName.pdf' does not contain a layer with the name 'þÿ'
endet nicht mit dem Text þÿEbene _XXX. Sie wird nach
der internen Byte-Order-Markierung abgeschnitten:
Im praktischen Betrieb trat einmal ein Problem auf, bei dem ein „non-breaking space“ in den Testdaten enthalten war, das zunächst als normales Leerzeichen wahrgenommen wurde. Der String-Vergleich lieferte aber einen Fehler, der erst durch die Verwendung von Unicode beseitigt werden konnte:
@Test public void nodeValueWithUnicodeValue() throws Exception { String filename = "documentUnderTest.pdf"; DefaultNamespace defaultNS = new DefaultNamespace("http://www.w3.org/1999/xhtml"); String nodeValue = "The code ... the button's"; String nodeValueWithNBSP = nodeValue + "\u00A0"; // The content terminates with a NBSP. XMLNode nodeP7 = new XMLNode("default:p[7]", nodeValueWithNBSP, defaultNS); AssertThat.document(filename) .hasXFAData() .withNode(nodeP7) ; }