| Zurück | Weiter |
Ein Zusammenschluss von Verbänden und Unternehmen der Wirtschaft und des Öffentlichen Dienstes, das „Forum elektronische Rechnung Deutschland“ (FeRD), hat am 25.06.2014 die Version 1.0 eines XML-Formates für den Austausch elektronischer Rechnungen beschlossen. Die Spezifikation selber wird ZUGFeRD (Zentraler User Guide des Forums elektronische Rechnung Deutschland) genannt. Weitreichende Informationen findet man im Internet bei Wikipedia (ZUGFeRD) , bei 'FeRD' und bei der PDF-Association im 'Leitfaden zu PDF-A3 und ZUGFeRD'.
Viele Validierungstools überprüfen zwar die Übereinstimmung der XML-Daten mit der XML-Schema Spezifikation, nicht aber die Übereinstimmung der XML-Daten (unsichtbar) mit den Daten des gedruckten PDF-Dokumentes (sichtbar). Das ist mit PDFUnit einfach, sofern Sie einen Seitenbereich definieren können, in dem der zu prüfende Wert vorkommen muss.
Für Tests mit ZUGFeRD-Daten stehen diese Methoden zur Verfügung:
// Methods to test ZUGFeRD data: .hasZugferdData().matchingXPath(xpathExpression) .hasZugferdData().withNode(xmlNode) .compliesWith().zugferdSpecification()
Die folgenden Beispiele beziehen sich auf das vom ZUGFeRD-Standard 1.0 mitgelieferte Beispiel-Dokument 'ZUGFeRD_1p0_BASIC_Einfach.pdf'. In jedem Beispiel wird zuerst der Test mit PDFUnit gezeigt, dann der dazugehörende Teil des PDF-Dokumentes und der XML-Daten.
Wenn Sie die ZUGFeRD-Daten eines Dokumentes sehen wollen, exportieren Sie sie am einfachsten, indem Sie das Dokument mit dem Adobe Reader® öffnen und von dort aus die angezeigte Datei 'ZUGFeRD-invoice.xml' speichern.
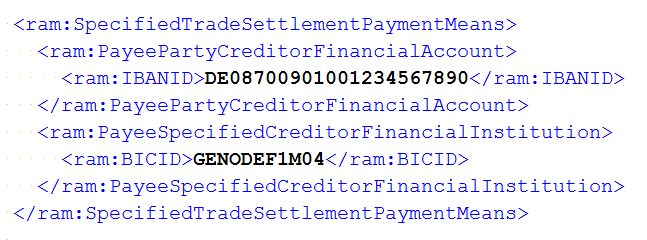
In diesem Beispiel wird ein Wert für die IBAN sowohl in den XML-Daten,
als auch im PDF-Text gesucht. Das geschieht mit zwei AssertThat-Anweisungen.
Für die Suche auf der PDF-Seite muss der passende Ausschnitt
(regionIBAN) und für die Suche in den XML-Daten der Name
des XML-Knotens angegeben werden (nodeIBAN).
@Test public void validateIBAN() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String expectedIBAN = "DE08700901001234567890"; XMLNode nodeIBAN = new XMLNode("ram:IBANID", expectedIBAN); PageRegion regionIBAN = createRegionIBAN(); AssertThat.document(filename) .hasZugferdData() .withNode(nodeIBAN) ; AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionIBAN) .hasText() .containing(expectedIBAN, WhitespaceProcessing.IGNORE) ; }
Ausschnitt der PDF-Seite:
 |
Ausschnitt der ZUGFeRD Daten:
 |
Es geht aber noch einfacher, nämlich mit hasText().containingZugferdData(xmlNode).
Die Methode extrahiert zuerst den Text aus dem angegebenen ZUGFeRD-Knoten und vergleicht diesen Text dann
mit dem sichtbaren Text des angegebenen Seitenausschnitts.
Der Vergleich findet intern mit der Funktion containing() statt, d.h.
der XML-Text muss irgendwo im Seitenausschnitt gefunden werden. Zusätzlicher Text
im Seitenausschnitt ist erlaubt.
@Test public void validateIBAN_simplified() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; XMLNode nodeIBAN = new XMLNode("ram:IBANID"); PageRegion regionIBAN = createRegionIBAN(); AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionIBAN) .hasText() .containingZugferdData(nodeIBAN) ; }
Wichtig zu wissen: Bei dem Vergleich werden alle Leerzeichen ignoriert. Das ist notwendig, denn Zeilenumbrüche und formatierende Leerzeichen haben im sichtbaren Text auf der PDF-Seite und innerhalb des unsichtbaren XML-Textes eine ganz verschiedene Bedeutung und sind demzufolge selten gleich.
Der vereinfachte Funktionsaufruf des vorigen Beispiels funktioniert aber nur,
wenn die XML-Daten als Ganzes im vorgegebenen Seitenausschnitt enthalten sind.
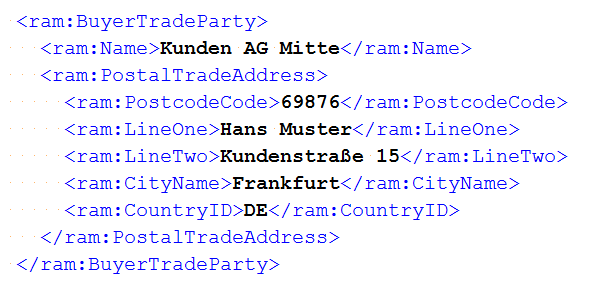
Im folgenden Beispiel steht die Postleitzahl in den XML-Daten getrennt vom Städtename getrennt.
Deshalb muss für die Überprüfung der Rechnungsanschrift
wieder mit zwei AssertThat-Aufrufen gearbeitet werden.
Weil der zu prüfende Text nur ein Teil des XML-Knotens ist, enthält
der XPath-Ausdruck die Funktion contains(). Der Knoten
ram:PostalTradeAddress enthält zusätzlich noch den Wert 'DE',
der aber nicht im sichtbaren Text vorkommt.
@Test public void validatePostalTradeAddress() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String expectedAddressPDF = "Hans Muster " + "Kundenstraße 15 " + "69876 Frankfurt"; String expectedAddressXML = "Hans Muster " + "Kundenstraße 15 " + "Frankfurt"; String addressXMLNormalized = WhitespaceProcessing.NORMALIZE.process(expectedAddressXML); String xpathWithPlaceholder = "ram:BuyerTradeParty/ram:PostalTradeAddress[contains(normalize-space(.), '%s')]"; String xpathPostalTradeAddress = String.format(xpathWithPlaceholder, addressXMLNormalized); XMLNode nodePostalTradeAddress = new XMLNode(xpathPostalTradeAddress); PageRegion regionPostalTradeAddress = createRegionPostalAddress(); AssertThat.document(filename) .hasZugferdData() .withNode(nodePostalTradeAddress) ; AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionPostalTradeAddress) .hasText() .containing(expectedAddressPDF) ; }
In diesem Test unterscheiden sich die Whitespaces im PDF-Dokument von denen in den
XML-Daten. Deshalb muss der XPath-Ausdruck die Funktion normalize-space() enthalten.
Ausschnitt der PDF-Seite:
 |
Ausschnitt der ZUGFeRD Daten:
 |
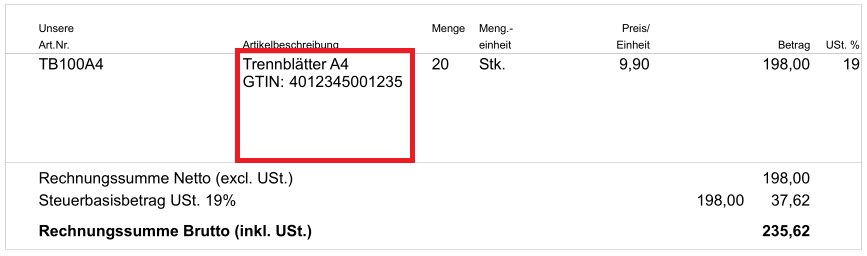
Das Neue am folgenden Beispiel ist die Tatsache, dass sich die Reihenfolge
der Textteile des zu prüfenden Textes im PDF und in den XML-Daten unterscheidet.
Deshalb kann nicht auf die zusammenhängende Artikelbezeichnung 'Trennblätter A4 GTIN: 4012345001235'
geprüft werden. Der Test validiert lediglich 'GTIN: 4012345001235'. Dafür
wird in XPath die Funktion contains() und in PDFUnit die Funktion
hasText().containing() benutzt.
@Test public void validateTradeProduct() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String expectedTradeProduct = "GTIN: 4012345001235"; String xpathWithPlaceholder = "ram:SpecifiedTradeProduct/ram:Name[contains(., '%s')]"; String xpathTradeProduct = String.format(xpathWithPlaceholder, expectedTradeProduct); XMLNode nodeTradeProduct = new XMLNode(xpathTradeProduct); PageRegion regionTradeProduct = createRegionTradeProduct(); AssertThat.document(filename) .hasZugferdData() .withNode(nodeTradeProduct) ; AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionTradeProduct) .hasText() .containing(expectedTradeProduct) ; }
Ausschnitt der PDF-Seite:
 |
Ausschnitt der ZUGFeRD Daten:
 |
Es gibt gelegentlich den Wunsch, anspruchsvolle Prüfungen auf die XML-Daten
anzuwenden. Diesen Wunsch unterstützt PDFUnit, indem es die Methode
matchingXPath(..) zur Verfügung stellt, mit der das volle
Potential von XPath auf die ZUGFeRD-Daten losgelassen werden kann.
Das folgende Beispiel überprüft, dass die Anzahl der fakturierten Artikel (TradeLineItems) genau '1' ist.
@Test public void hasZugferdDataMatchingXPath() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String xpathNumberOfTradeItems = "count(//ram:IncludedSupplyChainTradeLineItem) = 1"; XPathExpression exprNumberOfTradeItems = new XPathExpression(xpathNumberOfTradeItems); AssertThat.document(filename) .hasZugferdData() .matchingXPath(exprNumberOfTradeItems) ; }
Ausschnitt der ZUGFeRD Daten:
 |
Noch anspruchsvoller ist es, mit Hilfe von XPath zu prüfen, dass die Summe der Preise aller bestellten Artikel der Gesamtsumme (netto) entspricht, die an anderer Stelle im Dokument gespeichert ist. Ob eine solche Prüfung Gegenstand automatisierter Tests ist oder eher eine Prüfung in der Produktionsumgebung, darf gefragt werden. Aber sie zeigt, wie einfach es ist, komplizierte Prüfungen auf ZUGFeRD-Daten durchzuführen:
@Test public void hasZugferdData_TotalAmountWithoutTax() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String xpTotalAmount = "sum(//ram:IncludedSupplyChainTradeLineItem//ram:LineTotalAmount)" + " = " + "sum(//ram:TaxBasisTotalAmount)"; XPathExpression exprTotalAmount = new XPathExpression(xpTotalAmount); AssertThat.document(filename) .hasZugferdData() .matchingXPath(exprTotalAmount) ; }
Um einen solchen XPath-Ausdruck zu entwickeln, müssen Ihnen die XML-Daten vorliegen.
Sie können die ZUGFeRD entweder aus dem Adobe Reader® speichern (rechte Maustaste) oder
Sie extrahieren sie mit dem Hilfsprogramm ExtractZugferdData von PDFUnit.
Es ist in Kapitel
9.15: „ZUGFeRD-Daten extrahieren“
beschrieben.
Als Letztes muss noch erwähnt werden, dass PDFUnit auch die Einhaltung der ZUGFeRD-Spezifikation überprüfen kann:
@Test public void compliesWithZugferdSpecification() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; AssertThat.document(filename) .compliesWith() .zugferdSpecification(ZugferdVersion.VERSION10) ; }