| Zurück | Weiter |
PDF-Dokumente enthalten Informationen über Titel, Autor, Stichworte/Keywords und weitere Eigenschaften. Diese vom PDF-Standard vorgegebenen Informationen können durch individuelle Key-Value-Paare erweitert werden. Im Zeitalter von Suchmaschinen und Archivsystemen spielen sie eine zunehmend große Rolle. Umso wichtiger ist es, die Metadaten mit ordentlichen Werten zu füllen.
Ein Beispiel für schlechte Dokumenteneigenschaften aus der Realität ist ein PDF-Dokument mit dem Titel „jfqd231.tmp“ (das ist tatsächlich der Titel des Dokumentes). Mit diesem Titel wird es nie gesucht und gefunden werden. Bei diesem Dokument einer amerikanischen Behörde handelt es sich um ein eingescanntes Schriftstück aus der Schreibmaschinenzeit. Es wurde 1993 eingescannt. Da aber auch der Dateiname eine semantikfreie Zahlenfolge ist, ist der Nutzen dieses Dokumentes nur marginal größer, als wenn es nicht existierte.
Folgende Tags stehen zur Validierung der Metadaten zur Verfügung:
<!-- Tags to test document properties: --> <hasAuthor /> <hasCreator /> <hasKeywords /> <hasProducer /> <hasProperty /> <hasSubject /> <hasTitle /> <hasNoAuthor /> <hasNoCreator /> <hasNoKeywords /> <hasNoProducer /> <hasNoProperty /> <hasNoSubject /> <hasNoTitle /> <hasCreationDate /> <hasCreationDateAfter /> <hasCreationDateBefore /> <hasModificationDate /> <hasModificationDateAfter /> <hasModificationDateBefore /> <hasNoCreationDate /> <hasNoModificationDate />
Metadaten eines Test-Dokumentes können auch mit den Metadaten eines anderen PDF-Dokumentes verglichen werden. Solche Vergleiche sind in Kapitel 4.7: „Dokumenteneigenschaften vergleichen“ beschrieben.
Sie können den Autor eines Dokumentes manuell im PDF-Reader überprüfen. Einfacher geht es aber mit automatisierten Tests.
Wenn das Dokument einen beliebigen Wert für den Autor enthalten soll, können Sie das so testen:
<testcase name="hasAuthor"> <assertThat testDocument="documentInfo/documentInfo_allInfo.pdf"> <hasAuthor /> </assertThat> </testcase>
Um explizit zu prüfen, dass die Dokumenteneigenschaft Autor nicht vorhanden,
muss das Tag <hasNoAuthor /> verwendet werden:
<testcase name="hasNoAuthor"> <assertThat testDocument="documentInfo_noAuthorTitleSubjectKeywordsApplication.pdf"> <hasNoAuthor /> </assertThat> </testcase>
Der nächste Test überprüft den Wert der Eigenschaft „Autor“:
<testcase name="hasAuthor_matchingComplete"> <assertThat testDocument="documentInfo/documentInfo_allInfo.pdf"> <hasAuthor> <matchingComplete>PDFUnit.com</matchingComplete> </hasAuthor> </assertThat> </testcase>
Verschiedene Tags zum Vergleichen von Texten stehen zur Verfügung. Deren Namen sind selbsterklärend:
<!-- Comparing text for author, creator, keywords, producer, subject, title: --> <containing /> <endingWith /> <matchingComplete /> <matchingRegex /> <notContaining /> <notMatchingRegex /> <startingWith />
Bei allen Vergleichen werden Leerzeichen nicht verändert. Bei so kurzen Feldern obliegt die Verantwortung über die Leerzeichen dem Testentwickler.
Alle Vergleiche arbeiten case-sensitiv.
Die Umsetzung des Tags <matchingRegex /> folgt den Regeln von
java.util.regex.Pattern
.
Die Tests auf Inhalte von Creator, Keywords, Producer, Subject und Title funktionieren genauso wie zuvor für „ Autor“ beschrieben.
Für jede Dokumenteneigenschaft gibt es die Tags <hasXXX />
und <hasNoXXX />.
Die Tags zum inhaltlichen Vergleich einer Dokumenteneigenschaft können auch gleichzeitig verwendet werden:
<!-- Multiple string comparisons are possible --> <testcase name="hasKeywords_allTextComparingTags"> <assertThat testDocument="documentInfo/documentInfo_allInfo.pdf"> <hasKeywords> <notContaining>--</notContaining> </hasKeywords> <hasKeywords> <matchingRegex>.*key.*</matchingRegex> </hasKeywords> <hasKeywords> <startingWith>PDFUnit</startingWith> </hasKeywords> </assertThat> </testcase>
Diese Art Test ist aber nicht empfehlenswert, weil der Name des Tests nicht spezifisch genug ausgedrückt werden kann.
Die in den vorhergehenden Abschnitten gezeigten Prüfungen auf Standardeigenschaften
können alle auch mit dem allgemeinen Tag <hasProperty />
ausgeführt werden:
<testcase name="hasProperty_StandardProperties"> <assertThat testDocument="customproperties/Leitfaden_Elektronische_Signatur.pdf"> <hasProperty name="Title"> <matchingComplete>PDFUnit sample - Demo for Document Infos</matchingComplete> </hasProperty> <hasProperty name="Subject"> <matchingComplete>Demo for Document Infos</matchingComplete> </hasProperty> <hasProperty name="CreationDate"> <matchingComplete>D:20131027172417+01'00'</matchingComplete> </hasProperty> <hasProperty name="ModDate"> <matchingComplete>D:20131027172417+01'00'</matchingComplete> </hasProperty> </assertThat> </testcase>
<hasProperty /> prüft eine beliebige Dokumenteneigenschaft
als Key/Value-Paar.
Das im folgenden Beispiel benutzte Dokument besitzt zwei individuelle Key/Value-Werte, wie der Adobe Reader® zeigt:
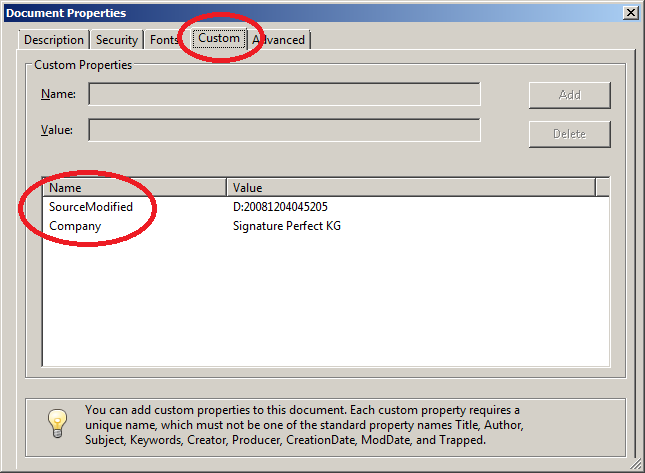
Der Test auf die Existenz dieser individuellen Eigenschaften mit konkreten Werten sieht dann so aus:
<testcase name="hasProperty_CustomProperties"> <assertThat testDocument="customproperties/Leitfaden_Elektronische_Signatur.pdf"> <hasProperty name="Company"> <matchingComplete>Signature Perfect KG</matchingComplete> </hasProperty> <hasProperty name="SourceModified"> <matchingComplete>D:20081204045205</matchingComplete> </hasProperty> </assertThat> </testcase>
Um sicherzustellen, dass eine bestimmte „Custom-Property“ nicht im PDF-Dokument auftaucht, muss der Test so aussehen:
<testcase name="hasNoProperty"> <assertThat testDocument="customproperties/Leitfaden_Elektronische_Signatur.pdf"> <hasNoProperty name="OldProperty_ShouldNotExist" /> </assertThat> </testcase>
Ab PDF-1.4 existiert die Möglichkeit, Metadaten intern als XML zu speichern (Extensible Metadata Platform, XMP). Das Kapitel 3.30: „XMP-Daten“ geht darauf ausführlich ein.