| Zurück | Weiter |
PDFUnit enthält das Hilfprogramm ExtractBookmarks.
Es exportiert Lesezeichen/Bookmarks von PDF-Dokumenten nach XML.
Das Kapitel
3.17: „Lesezeichen (Bookmarks) und Sprungziele“
beschreibt die Verwendung der erzeugten XML-Datei für Bookmarks-Tests.
:: :: Extract bookmarks from a PDF document into an XML file :: @echo off setlocal set CLASSPATH=./lib/pdfunit-2015.10/*;%CLASSPATH% set CLASSPATH=./lib/itext-5.5.1/*;%CLASSPATH% set CLASSPATH=./lib/bouncycastle-jdk15on-150/*;%CLASSPATH% set TOOL=com.pdfunit.tools.ExtractBookmarks set OUT_DIR=./tmp set IN_FILE=diverseContentOnMultiplePages.pdf set PASSWD= java %TOOL% %IN_FILE% %OUT_DIR% %PASSWD% endlocal
Die zu bearbeitende Datei heißt diverseContentOnMultiplePages.pdf
und ist ein Beispieldokument mit 4 Bookmarks:
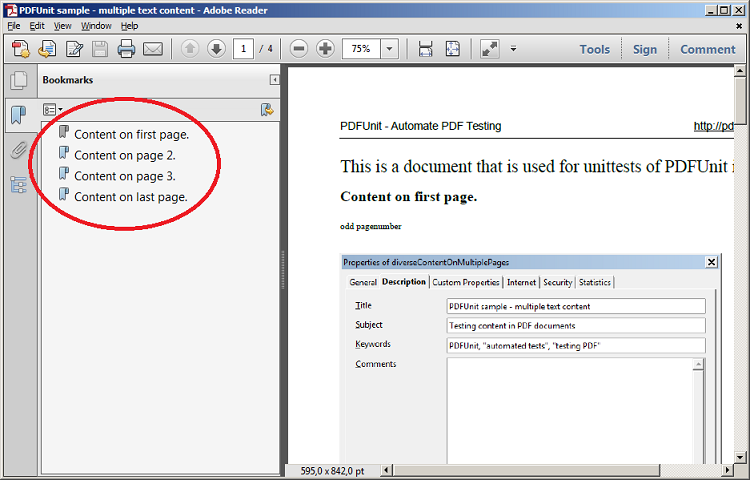
Die erzeugte Datei _bookmarks_diverseContentOnMultiplePages.out.xml
kann für XML-basierte Tests verwendet werden:
<?xml version="1.0" encoding="UTF-8"?> <Bookmark> <Title Action="GoTo" Page="1 XYZ 56.7 745 0" >Content on first page.</Title> <Title Action="GoTo" Page="2 XYZ 56.7 745 0" >Content on page 2.</Title> <Title Action="GoTo" Page="3 XYZ 56.7 733.5 0" >Content on page 3.</Title> <Title Action="GoTo" Page="4 XYZ 56.7 733.5 0" >Content on last page.</Title> </Bookmark>
PDFUnit nutzt intern die statische Methode SimpleBookmark.getBookmark(PdfReader)
von iText. Herzlichen Dank an die Entwickler.