| Zurück | Weiter |
Wie in Kapitel 3.19: „Schriften“
beschrieben, bergen Schriften eine Komplexität, die ruhig öfter getestet werden sollte.
Sie können alle Informationen über Schriften mit dem Hilfsprogramm ExtractFontsInfo
als XML-Datei aus PDF extrahieren, um darauf mit XPath vielseitige Tests zu entwickeln.
Der Algorithmus, der die XML-Datei erzeugt, ist der gleiche, der auch von den PDFUnit-Tests verwendet wird.
:: :: Extract information about fonts used in a PDF document into an XML file :: @echo off setlocal set CLASSPATH=./lib/pdfunit-2015.10/*;%CLASSPATH% set CLASSPATH=./lib/itext-5.5.1/*;%CLASSPATH% set CLASSPATH=./lib/bouncycastle-jdk15on-150/*;%CLASSPATH% set TOOL=com.pdfunit.tools.ExtractFontsInfo set OUT_DIR=./tmp set IN_FILE=fonts_11_japanese.pdf set PASSWD= java %TOOL% %IN_FILE% %OUT_DIR% %PASSWD% endlocal
Der Adobe Reader® zeigt folgende Schriften des japanischen PDF-Dokumentes
fonts_11_japanese.pdf:
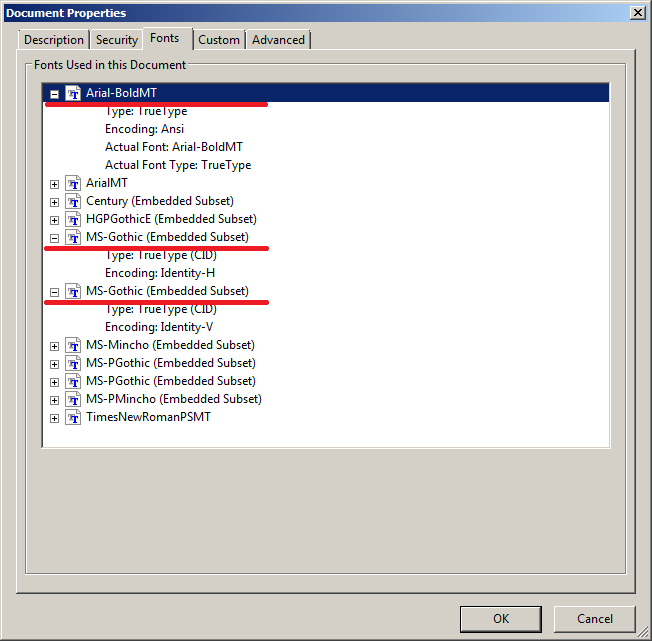
Die markierten Namen sind auch in der erzeugten Ausgabedatei
_fontinfo_fonts_11_japanese.out.xml enthalten:
<?xml version="1.0" encoding="UTF-8" ?> <fontlist> ... <font name="Arial-BoldMT" baseFontName="Arial-BoldMT" type="TrueType" embedded="false" encoding="WinAnsiEncoding" convertibleToUnicode="false" /> <font name="MDOLLI+MS-Gothic" baseFontName="MS-Gothic" type="CIDFontType2" embedded="true" convertibleToUnicode="false" /> <font name="MDOLLI+MS-Gothic" baseFontName="MS-Gothic" type="Type0" embedded="false" encoding="Identity-H" convertibleToUnicode="true" /> ... </fontlist>
Die XML-Datei listet jedes Subset einer Schriftart einzeln auf. Dadurch ergeben sich Abweichungen von der Anzeige durch den Adobe Reader®.
Sie können die Datei beliebig formatieren, ohne dass dadurch die Tests beeinflusst werden, weil Whitespaces zwischen Elementen und Attributen nach den Regeln von XML sowieso keine Rolle spielen.
Auf der Basis dieser Datei können Sie mit einem geeigneten XPath-Ausdruck beliebige Eigenschaften von Schriften testen.