| Zurück | Weiter |
Mit dem Programm ExtractXFAData können Sie XFA-Daten exportieren und
anschließend zusammen mit XPath in Tests verwenden, wie es in Kapitel
3.29: „XFA Daten“
gezeigt wird.
:: :: Extract XFA data of a PDF document as XML :: @echo off setlocal set CLASSPATH=./lib/pdfunit-2015.10/*;%CLASSPATH% set CLASSPATH=./lib/itext-5.5.1/*;%CLASSPATH% set CLASSPATH=./lib/bouncycastle-jdk15on-150/*;%CLASSPATH% set TOOL=com.pdfunit.tools.ExtractXFAData set OUT_DIR=./tmp set IN_FILE=xfa-enabled.pdf set PASSWD= java %TOOL% %IN_FILE% %OUT_DIR% %PASSWD% endlocal
Als Eingabe für das Skript dient die Datei xfa-enabled.pdf,
ein Beispieldokument von iText.
Die erzeugte XML-Datei _xfadata_xfa-enabled.out.xml ist sehr
groß. Deshalb wurden im folgenden Bild einige XML-Tags zusammengefaltet, um einen
besseren Eindruck zu vermitteln:
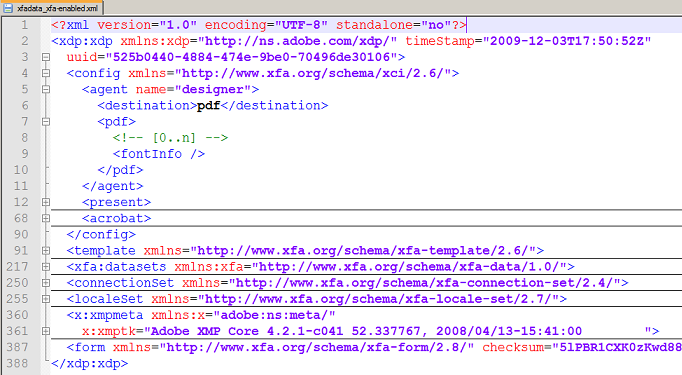 |
Das Extraktionsprogramm nutzt intern die Methode XfaForm.getDomDocument()
von iText (http://www.itextpdf.com).