| Prev | Next |
On 25.06.2014, the 'Forum elektronische Rechnung Deutschland' (FeRD), an association of organizations and companies of the industry and the public sector, published version 1.0 of an XML format for electronic invoices. The specification is called ZUGFeRD (Zentraler User Guide des Forums elektronische Rechnung Deutschland). Detailed information is available online at Wikipedia (ZUGFeRD, german) , at 'FeRD' (german) and in a publication of the PDF-Association 'ZUGFeRD 1.0 – English Version'.
Many validation tools check whether the XML data comply with the XML-Schema specification, but do not check whether the invisible XML data are in accordance with the visible data of the printed PDF document. That is easy to do with PDFUnit, if you know the page region of the data to be checked.
PDFUnit provides the following methods for testing ZUGFeRD data:
// Methods to test ZUGFeRD data: .hasZugferdData().matchingXPath(xpathExpression) .hasZugferdData().withNode(xmlNode) .compliesWith().zugferdSpecification()
The next examples refer to the document 'ZUGFeRD_1p0_BASIC_Einfach.pdf' which is provided together with the specification files of the ZUGFeRD standard version 1.0. Each example shows first the Java code, then the related part of the printed PDF document, and lastly the corresponding XML data.
If you want to make the ZUGFeRD data visible, simply open the PDF with Adobe Reader® and save the file 'ZUGFeRD-invoice.xml'.
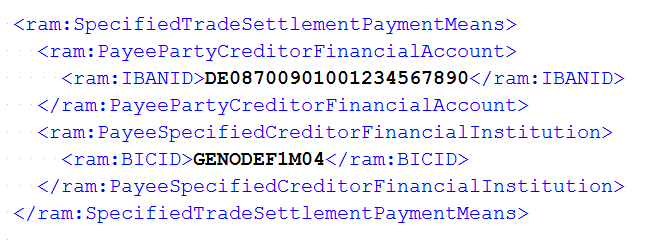
In this example, an IBAN value is expected both in the XML data
and in the PDF text. The test is performed using two AssertThat statements.
To point the test to the expected regions, a page region (regionIBAN)
is defined for the visible PDF data and an XML node (nodeIBAN)
is defined for the ZUGFeRD data.
@Test public void validateIBAN() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String expectedIBAN = "DE08700901001234567890"; XMLNode nodeIBAN = new XMLNode("ram:IBANID", expectedIBAN); PageRegion regionIBAN = createRegionIBAN(); AssertThat.document(filename) .hasZugferdData() .withNode(nodeIBAN) ; AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionIBAN) .hasText() .containing(expectedIBAN, WhitespaceProcessing.IGNORE) ; }
Section of the PDF page:
 |
Section of the ZUGFeRD data:
 |
But the previous test can be simplified by using the method hasText().containingZugferdData(xmlNode).
Internally, that method first extracts the text from the ZUGFeRD data and
then compares it with the visible text of the given page region.
For that comparison, the method containing() is used. This means that
the ZUGFeRD data must exist somewhere within the given page region. The page region may also contain
additional text.
@Test public void validateIBAN_simplified() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; XMLNode nodeIBAN = new XMLNode("ram:IBANID"); PageRegion regionIBAN = createRegionIBAN(); AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionIBAN) .hasText() .containingZugferdData(nodeIBAN) ; }
Important: The whitespaces are removed before the two values are compared. This is necessary because line breaks and formatting spaces have different meanings in XML and PDF.
The simplified check in the previous example works fine if the XML data
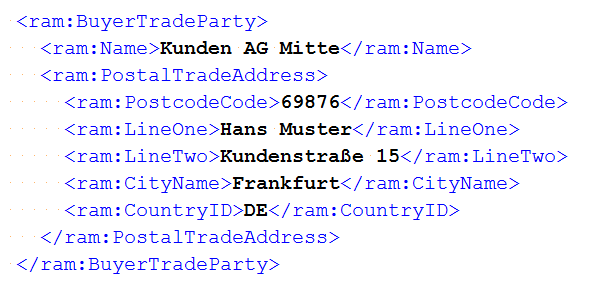
represent the visible data. But in the following example the ZIP code in the ZUGFeRD data
is separated from the city name.
So two invocations of AssertThat are needed to validate the complete address.
The XPath expression uses the XPath function contains() because
the expected value is a part of the complete node value. The node value
ends with 'DE' which is not part of the visible text.
@Test public void validatePostalTradeAddress() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String expectedAddressPDF = "Hans Muster " + "Kundenstraße 15 " + "69876 Frankfurt"; String expectedAddressXML = "Hans Muster " + "Kundenstraße 15 " + "Frankfurt"; String addressXMLNormalized = WhitespaceProcessing.NORMALIZE.process(expectedAddressXML); String xpathWithPlaceholder = "ram:BuyerTradeParty/ram:PostalTradeAddress[contains(normalize-space(.), '%s')]"; String xpathPostalTradeAddress = String.format(xpathWithPlaceholder, addressXMLNormalized); XMLNode nodePostalTradeAddress = new XMLNode(xpathPostalTradeAddress); PageRegion regionPostalTradeAddress = createRegionPostalAddress(); AssertThat.document(filename) .hasZugferdData() .withNode(nodePostalTradeAddress) ; AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionPostalTradeAddress) .hasText() .containing(expectedAddressPDF) ; }
The whitespaces in the PDF document differ from those in the XML data.
Therefore, the XPath function normalize-space() is used.
Section of the PDF page:
 |
Section of the ZUGFeRD data:
 |
But text in a PDF file does not always correspond with the text of a
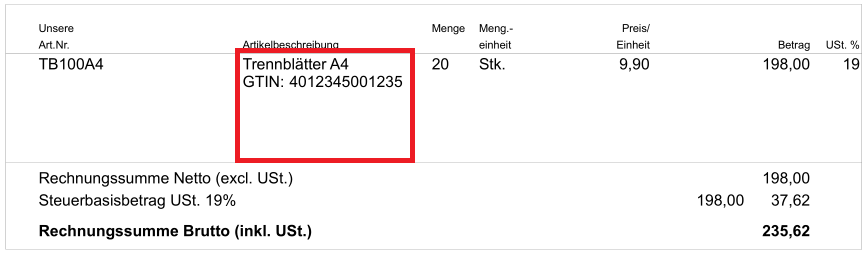
node in the ZUGFeRD data. That's why in the next example the string
'Trennblätter A4 GTIN: 4012345001235' cannot be validated.
Only the String 'GTIN: 4012345001235' can be validated.
The XPath expression thus needs to use the function contains()
and the PDFUnit method needs to use hasText().containing().
@Test public void validateTradeProduct() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String expectedTradeProduct = "GTIN: 4012345001235"; String xpathWithPlaceholder = "ram:SpecifiedTradeProduct/ram:Name[contains(., '%s')]"; String xpathTradeProduct = String.format(xpathWithPlaceholder, expectedTradeProduct); XMLNode nodeTradeProduct = new XMLNode(xpathTradeProduct); PageRegion regionTradeProduct = createRegionTradeProduct(); AssertThat.document(filename) .hasZugferdData() .withNode(nodeTradeProduct) ; AssertThat.document(filename) .restrictedTo(FIRST_PAGE) .restrictedTo(regionTradeProduct) .hasText() .containing(expectedTradeProduct) ; }
Section of the PDF page:
 |
Section of the ZUGFeRD data:
 |
For more complex validations, PDFUnit provides the method matchingXPath(..).
This method makes it possible to use the full power of XPath in combination with
ZUGFeRD data.
The next example checks that the number of traded articles is exactly '1'.
@Test public void hasZugferdDataMatchingXPath() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String xpathNumberOfTradeItems = "count(//ram:IncludedSupplyChainTradeLineItem) = 1"; XPathExpression exprNumberOfTradeItems = new XPathExpression(xpathNumberOfTradeItems); AssertThat.document(filename) .hasZugferdData() .matchingXPath(exprNumberOfTradeItems) ; }
Section of the ZUGFeRD data:
 |
It is even more challenging to check that the summed up prices of all articles are equal to the given sum which is stored separately in the ZUGFeRD data. But with a little XPath the test can be performed as follows:
@Test public void hasZugferdData_TotalAmountWithoutTax() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; String xpTotalAmount = "sum(//ram:IncludedSupplyChainTradeLineItem//ram:LineTotalAmount)" + " = " + "sum(//ram:TaxBasisTotalAmount)"; XPathExpression exprTotalAmount = new XPathExpression(xpTotalAmount); AssertThat.document(filename) .hasZugferdData() .matchingXPath(exprTotalAmount) ; }
You can develop such a test only if you have direct access to the XML data.
The ZUGFeRD data can either be exported from the PDF by using Adobe Reader® (right mouse button)
or extracted using the utility program ExtractZugferdData in PDFUnit.
This utility is described in chapter
9.15: “Extract ZUGFeRD Data”.
Lastly, it should be mentioned that PDFUnit can also be used to check the compliance of your ZUGFeRD data with the XML-Schema specification.
@Test public void compliesWithZugferdSpecification() throws Exception { String filename = "ZUGFeRD_1p0_BASIC_Einfach.pdf"; AssertThat.document(filename) .compliesWith() .zugferdSpecification(ZugferdVersion.VERSION10) ; }