| Prev | Next |
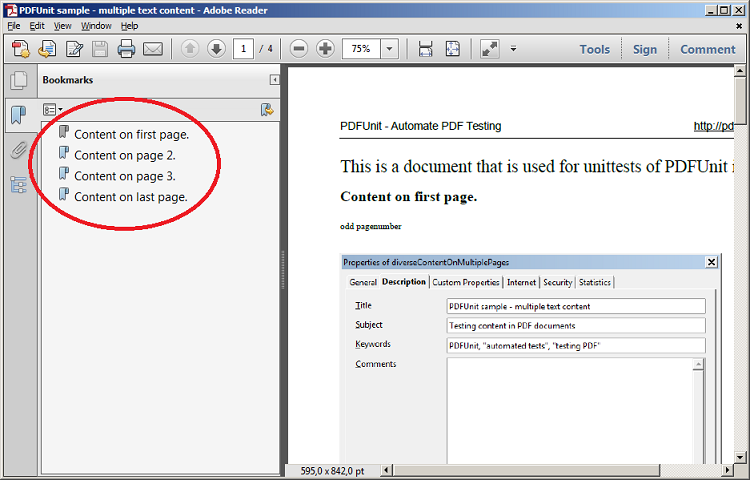
PDFUnit comes with the utility ExtractBookmarks
which exports bookmarks from PDF documents into an XML file.
Chapter 3.4: “Bookmarks and Named Destinations”
describes how to use this created XML file for bookmark tests.
:: :: Extract bookmarks from a PDF document into an XML file :: @echo off setlocal set CLASSPATH=./lib/pdfunit-2015.10/*;%CLASSPATH% set CLASSPATH=./lib/itext-5.5.1/*;%CLASSPATH% set CLASSPATH=./lib/bouncycastle-jdk15on-150/*;%CLASSPATH% set TOOL=com.pdfunit.tools.ExtractBookmarks set OUT_DIR=./tmp set IN_FILE=diverseContentOnMultiplePages.pdf set PASSWD= java %TOOL% %IN_FILE% %OUT_DIR% %PASSWD% endlocal
The output file _bookmarks_diverseContentOnMultiplePages.out.xml
can be used for XML-based tests:
<?xml version="1.0" encoding="UTF-8"?> <Bookmark> <Title Action="GoTo" Page="1 XYZ 56.7 745 0" >Content on first page.</Title> <Title Action="GoTo" Page="2 XYZ 56.7 745 0" >Content on page 2.</Title> <Title Action="GoTo" Page="3 XYZ 56.7 733.5 0" >Content on page 3.</Title> <Title Action="GoTo" Page="4 XYZ 56.7 733.5 0" >Content on last page.</Title> </Bookmark>
Internally, PDFUnit uses the method SimpleBookmark.getBookmark(PdfReader)
from iText. Many thanks to the developers of iText.