| Prev | Next |
As described in chapter 3.9: “Fonts”
fonts are a topic which need to be tested.
All information about fonts can be extracted using the utility ExtractFontsInfo.
You can use this generated file can for sophisticated tests with XPath.
The algorithm that generates the XML file is the same as the one used by the PDFUnit tests.
:: :: Extract information about fonts used in a PDF document into an XML file :: @echo off setlocal set CLASSPATH=./lib/pdfunit-2015.10/*;%CLASSPATH% set CLASSPATH=./lib/itext-5.5.1/*;%CLASSPATH% set CLASSPATH=./lib/bouncycastle-jdk15on-150/*;%CLASSPATH% set TOOL=com.pdfunit.tools.ExtractFontsInfo set OUT_DIR=./tmp set IN_FILE=fonts_11_japanese.pdf set PASSWD= java %TOOL% %IN_FILE% %OUT_DIR% %PASSWD% endlocal
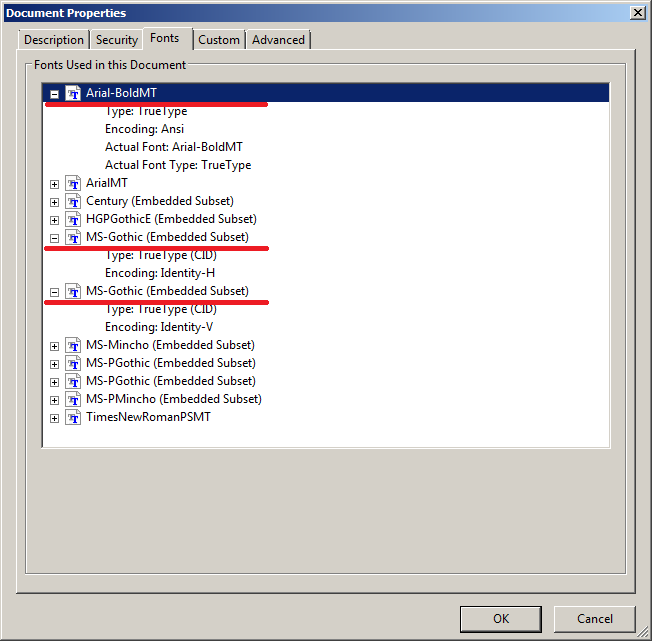
The output file _fontinfo_fonts_11_japanese.out.xml
contains the underlined names:
<?xml version="1.0" encoding="UTF-8" ?> <fontlist> ... <font name="Arial-BoldMT" baseFontName="Arial-BoldMT" type="TrueType" embedded="false" encoding="WinAnsiEncoding" convertibleToUnicode="false" /> <font name="MDOLLI+MS-Gothic" baseFontName="MS-Gothic" type="CIDFontType2" embedded="true" convertibleToUnicode="false" /> <font name="MDOLLI+MS-Gothic" baseFontName="MS-Gothic" type="Type0" embedded="false" encoding="Identity-H" convertibleToUnicode="true" /> ... </fontlist>
Because the XML file contains all subsets of a font it might differ from what Adobe Reader® shows.
You can format the resulting file as desired without affecting the test because whitespaces between elements and attributes are irrelevant to XML.
Based on this file, appropriate XPath expressions can be used to test any complex combination of field properties.